재현 데이터(Synthetic Data) 생성 - 라이브러리 (py-synthpop)
안녕하세요, 이번에 소개해드릴 라이브러리는 재현 데이터 생성에 자주 활용되는 py-synthpop(또는 synthpop)입니다.
| 1. 재현 데이터(Synthetic Data) 생성 - 개념 2. 재현 데이터(Synthetic Data) 생성 - 라이브러리 3. 재현 데이터(Synthetic Data) 생성 - 생성 기법 |
지난 포스팅 재현 데이터 개념과 SDV 라이브러리 글을 참고하면 도움이 됩니다.
SDV 라이브러리와 마찬가지로 정형 데이터를 가지고 재현하는 것으로 synthpop 소개 및 실습 예제를 보여드리겠습니다.
py-synthpop
py-synthpop는 R에 있는 패키지(라이브러리) synthpop을 파이썬에서 구현한 라이브러리이다.
재현 데이터 생성에서 꾸준히 활용되고 성능이 좋다고 알려진 CART 알고리즘을 사용하기 위해 synthpop 라이브러리를 사용한다고 할 수 있다.
대중적으로 신뢰하고 있는 GAN계열을 사용하고 싶다면 SDV 라이브러리를 사용하고, 성능이 좋은 CART를 사용하고 싶다면 py-synthpop을 사용하면 된다.

2020년 이후로 버전이 업그레이드되지 않아 파이썬 버전에 크게 영향을 미치지 않으며, 간단한 코드로 이뤄져 있다.
py-synthpop 실습 예제
1. py-synthpop 라이브러리 설치
pip install py-synthpop
2. 라이브러리 임포트 & 데이터 로드
캐글에 올라와있는 타이타닉 데이터셋을 이용하여 재현 데이터를 만들고자 한다.
py-synthpop을 import 할 때는 Synthpop으로 입력한다.
타이타닉은 891행 12열로 이뤄진 데이터이다.
import pandas as pd
from synthpop import Synthpop # py-synthpop
df = pd.read_csv('train.csv')
df.head()
3. 메타 데이터 작성
실제 데이터를 임의의 데이터로 재현하기 위해서는 메타 데이터가 필요하다.
데이터는 int, float, category 3가지로 분류하는 작업을 진행한다.
# Fonction de conversion
def convert_dict_types(input_dict):
# Mapping des types
type_mapping = {
'int64': 'int',
'int32': 'int',
'float32': 'float',
'float64': 'float',
'object': 'category'
}
# Création du nouveau dictionnaire
new_dict = {k: type_mapping[str(v)] for k, v in input_dict.items()}
return new_dict
타이타닉의 데이터 타입은 아래와 같다.
df.dtypes
dtypes = convert_dict_types(df.dtypes)
dtypes # 메타 데이터
4. 데이터 타입 변경
타이타닉 데이터의 칼럼들은 int, float, object로 되어 있으며, object는 데이터 타입을 변경하여 category로 바꿔준다.
Name의 경우 익명처리해야하지만, Name, Sex, Ticket, Cabin, Embarked 5개 칼럼 모두 바꿔서 작업했다.
익명처리가 필요할 경우 칼럼 삭제나 ID부여 등을 진행하면 된다.
# object -> category
for col in df.columns:
if df[col].dtype == 'object':
df[col] = df[col].astype('category')
5. synthpop 학습기 만들기
synthpop 학습기를 만들고, 학습을 진행한다.
타이타닉 실제 데이터와 데이터 타입을 반영한 메타 데이터(dict)를 함께 학습시킨다.
synthpop의 경우 CART 기법으로 데이터를 학습하며, int나 float는 회귀, category는 분류로 작업한다.
spop = Synthpop() # 재현 학습기
spop.fit(df, dtypes) # 실제 데이터, 메타 데이터 학습
6. 재현 데이터 생성
재현 데이터를 원하는 만큼 생성할 수 있어, 기존 실제 데이터 891 행보다 많은 1,000개를 생성해 본다.
df_syn = spop.generate(1000) # 1000개 재현 데이터 생성
df_syn.head()
7. 실제 데이터와 재현 데이터 비교
실제 데이터와 재현 데이터의 .head() output이다.
재현 데이터의 첫 행 'Hamalainen, Mrs. William (Anna)'을 가지고 실제 데이터에서 찾아봤다.
실제 데이터에서는 Hamalainen, Mrs. William (Anna)는 여성, 24살이고, 재현 데이터에서는 남성, 3살이다.
df.loc[df['Name'] == 'Hamalainen, Mrs. William (Anna)']
8. 비교 시각화
타이타닉 실제 데이터는 891개, 재현 데이터는 1,000개인 것을 인지한 상태로 비교해보려 한다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터프레임에 출처 칼럼 추가
df['source'] = 'Real'
df_syn['source'] = 'Synthetic'
# 두 데이터프레임 합치기
df_combined = pd.concat([df, df_syn])
# barplot 생성
plt.figure(figsize=(8, 6))
sns.countplot(x='Sex', hue='source', data=df_combined)
plt.title('Sex distribution in Real and Synthetic data')
plt.show()
남성과 여성의 빈도로 재현 데이터의 row수가 많아 여성과 남성 모두 많이 나왔지만, 실제 데이터에서 남성이 많은 것처럼 재현 데이터도 그대로 재현한 것을 볼 수 있다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 데이터프레임에 출처 칼럼 추가
df['source'] = 'Real'
df_syn['source'] = 'Synthetic'
# 두 데이터프레임 합치기
df_combined = pd.concat([df, df_syn])
# 각 성별의 비율 계산
df_combined['perc'] = df_combined.groupby(['Sex', 'source'])['Sex'].transform('count') / df_combined.groupby('source')['Sex'].transform('count')
# barplot 생성
plt.figure(figsize=(8, 6))
barplot = sns.barplot(x='Sex', y='perc', hue='source', data=df_combined, ci=None)
# 각 막대에 비율 텍스트 추가
for p in barplot.patches:
barplot.annotate(format(p.get_height(), '.1%'),
(p.get_x() + p.get_width() / 2., p.get_height()),
ha = 'center', va = 'center',
xytext = (0, 10),
textcoords = 'offset points')
plt.title('Sex distribution in Real and Synthetic data')
plt.show()
비율로 확인해 봤을 때 남성(64.8%)과 여성(35.2%)의 분포를 통계적으로 재현해 낸 것을 확인할 수 있다.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
sns.kdeplot(df['Age'], label='Real')
sns.kdeplot(df_syn['Age'], label='Synthetic')
plt.title('Age distribution in Real and Synthetic data')
plt.xlabel('Age')
plt.ylabel('Density')
plt.legend()
plt.show()
나이의 경우 분포를 비슷하게 재현했으며, 실제 데이터에서 많은 비중의 20~40대를 재현 데이터에서 많이 생성한 것을 볼 수 있다.
synthpop
국내에서 재현 데이터와 관련한 패키지를 검색하거나, 논문을 찾아보면 가장 많이 거론되는 패키지가 synthpop이다.
파이썬 사용자가 많고 기능도 많아, R에 대해 찾는 이가 적겠지만, R에서는 조금 더 커스텀하여 CART 성능을 높일 수 있다.
CART로 성능 높은 재현 데이터를 만들고 싶다면, R에서 도전해 보는 것도 좋다.
synthpop 실습 예제
1. synthpop 패키지 준비
synthpop 패키지를 설치하고 라이브러리로 불러온다.
##### 패키지 준비 #####
install.packages("synthpop")
library(synthpop)
library(dplyr)
2. 데이터 가져오기
타이타닉 데이터를 가져와 realdata 객체에 할당한다.
Name, Sex, Age, Parch, Pclass, Fare, Survived 총 7개의 칼럼을 가져오면서 Type라는 새로운 칼럼을 추가했다.
891행 8열을 가진 데이터이다.
realdata <- read.csv("train.csv") %>%
dplyr::select(Name, Sex, Age, Parch, Pclass, Fare, Survived) %>%
mutate(Type = "Real data") %>%
data.frame()
head(realdata)
3. 재현 데이터 생성
syn() 함수를 이용하여 실제 데이터와 CART 기법으로 재현 데이터를 생성한다.
syndata <- syn(realdata, method = "cart")
4. syndata 확인
syndata의 데이터 구조를 확인해 본다.
데이터는 list로 생성되어 있다. $syn 안에 데이터프레임이 존재하며, 891행 8열로 이뤄진 재현 데이터가 있다.
R의 synthpop은 실제 데이터의 행 개수와 같은 개수로 생성한다. 더 많은 행을 가지고 싶다면 파라미터(커스텀)를 조정해야 한다.
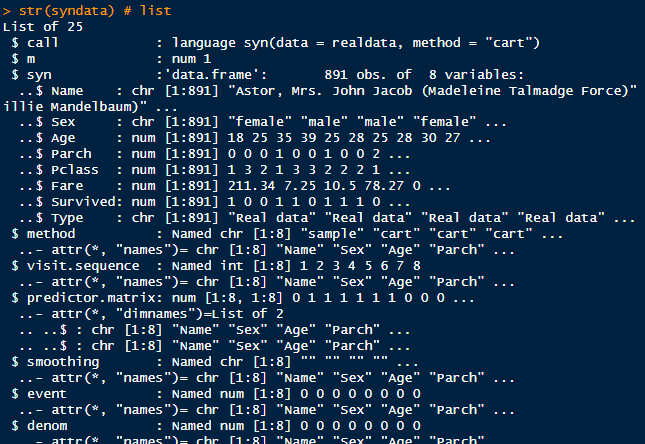
syndata를 확인하면, 1개의 데이터 셋을 만들었고, 재현 데이터의 데이터 프레임이 들어있다.
또한, 각 칼럼마다 어떤 기법으로 생성하였는지, 칼럼 생성 순서를 확인할 수 있다.

5. 실제 데이터와 재현 데이터 비교
실제 데이터와 재현 데이터의 head() output이다.

'Taussig, Mrs. Emil (Tillie Mandelbaum)'라는 이름을 가진 사람을 실제 데이터와 재현 데이터에서 조회를 해봤다.
실제 데이터를 유사하게 재현한 것은 좋지만 노출 위험이 있어, 익명 처리를 진행할 필요가 있다.

6. 검증 및 비교 시각화
compare() 함수를 이용하여 검증 결과와 시각화를 확인할 수 있다.
MSE를 확인하면, 'Sex'는 차이가 크게 없고 'Age', 'Fare', 'Parch'는 차이가 있어 plots창에 표현된다.
##### 비교 #####
compare(syndata, realdata, vars = c("Age", "Sex", "Fare", "Parch"))

마지막으로
R syn()을 자세하게 확인해보고 싶다면 ?syn()을 실행해 보길 바란다.
중요한 칼럼일수록 방문 순서(visit.sequence)를 변경하거나, 실제 데이터보다 더 많은 재현 데이터를 생성하고 seed 설정, Na값 처리 등 디테일하게 조정할 수 있다.
기술적으로 재현 데이터를 생성하는 방법을 마무리지으며, 어디서 어떻게 쓸지 생각해 보면, 외부로 데이터를 노출해야 하는 상황에 쓰이면 좋을 것이다. 대표적으로 공모전/대회를 추진하는 입장에서는 민감한 데이터를 가리고 데이터를 공유할 수 있다. 개인적으로는 보유하고 있는 가계부(엑셀, 앱) 데이터를 받아 재현 데이터를 생성하고, 분석을 진행하여 공개는 가능하나 분석 역량을 뽐낼 수 있는 개인 포트폴리오를 만들 수 있겠다.

Reference
저널
유성준,박나리(2020), "CART 기법을 이용한 개인신용정보 재현자료 생성 기법", 통계청 통계개발원
웹사이트
py-synthpop 깃허브, 접근일: 2024-01- 07, https://github.com/hazy/synthpop
py-synthpop PyPI 페이지, 접근일: 2024-01-07, https://pypi.org/project/py-synthpop/
py-synthpop piwheels, 접근일: 2024-01-07, https://www.piwheels.org/project/py-synthpop/
Iris Augment with SynthPop, 접근일: 2024-01-07, https://www.kaggle.com/code/mathurinache/iris-augment-with-synthpop
Synthetic Data Creation - Titanic Dataset, 접근일: 2024-01-07, https://www.kaggle.com/code/tombowe/synthetic-data-creation-titanic-dataset
synthpop 홈페이지, 접근일: 2024-01-07, https://www.synthpop.org.uk/
synthpop CRAN 페이지, 접근일: 2024-01-07, https://cran.r-project.org/web/packages/synthpop/index.html
synthpop: Bespoke Creation of Synthetic Data in R, 접근일: 2024-01-07, https://cran.r-project.org/web/packages/synthpop/vignettes/synthpop.pdf