재현 데이터(Synthetic Data) 생성 - 개념
안녕하세요. 이번 포스팅은 재현 데이터에 대한 시리즈를 준비했습니다.
글이 3개 이상이 될지 모르지만 개념, 라이브러리, 생성 기법에 대한 내용을 정리하려 합니다.
| 1. 재현 데이터(Synthetic Data) 생성 - 개념 2. 재현 데이터(Synthetic Data) 생성 - 라이브러리 3. 재현 데이터(Synthetic Data) 생성 - 생성 기법 |
재현 데이터를 사용하는 데이터 범위는 정형 데이터를 중심으로 기술했습니다.
재현 데이터 정의
재현 데이터(Synthetic Data)는 실제로 측정된 데이터(Real Data)가 아닌 인위적으로 새롭게 생성한 데이터
"합성 데이터라는 건 뭘까?"
Synthetic라는 영어 뜻이 '합성한, 인조의'라는 의미를 가지고 있어, 번역을 거쳐 합성 데이터 또는 인조 데이터라고 불리기도 하지만 국내에서는 정의를 내포한 재현 데이터를 많이 사용한다.
재현 데이터 생성 목적
재현 데이터를 생성하는 목적은 1. 개인정보 보호, 2. 모델 학습을 하기 위해 생성한다.
1. 개인정보 보호: 비식별 처리 방식 중 하나로 개인정보, 민감정보를 숨기기 위한 목적으로 사용
2. 모델 학습: 임의의 데이터를 생성하여 부족한 실제 데이터에 추가적으로 모델 학습을 하기 위한 용도
단, 모델 학습의 경우 이미지 데이터에서 많이 활용하며, 정형(테이블) 데이터에서는 계속 연구를 진행하고 있다.
그 밖에 비즈니스의 요구에 맞는 재현 데이터 생성, 실제 데이터보다 생성을 통한 비용 감소, 짧은 시간 내 데이터 셋 생성 및 이용으로 재현 데이터를 생성하려 한다.
재현 데이터 활용
"그럼, 재현 데이터를 생성해서 어디서, 어떻게 쓰려고 하는데?"
기업 및 기관 성격마다 다르지만,
1. 개인정보 보호가 중요한 분야(의료, 금융 등)에서 재현 데이터를 생성하고 있음
예를 들어, 의료분야에서는 한 개인의 질병 여부, 장애 등급 등이 민감정보이며, 금융분야에서는 신용카드번호, 신용점수, 대출금액 등 민감 정보가 대표적이다.
따라서, 재현 데이터의 발전은 데이터 3법과 같은 법의 규제에 영향을 받는다.
2. 데이터 부족을 해결하여 학생 및 연구자에게 사전테스트, 교육용으로 재현 데이터를 제공하고 있음
데이터가 많이 쌓여있는 공공기관이나 긴 시간 동안 빠르게 데이터가 쌓인 금융기관에서 데이터를 제공하여 데이터 관련 인력을 양성하고, 연구하여 데이터 산업 발전에 기여하고 있다.
3. 이미지(비정형) 데이터의 경우 재현 데이터를 생성하여 학습 데이터로 쓰임
이미지 관련 AI를 만드는 민간기업에서 활발히 활용하고 있으며, 명도/채도 변환, 방향 전환 등으로 재현 데이터를 생성한다.

재현 데이터 분류
1. 완전 재현 데이터(Fully Synthetic Data): 실제 데이터(Real Data)가 전혀 사용되지 않은 데이터
2. 부분 재현 데이터(Partially Synthetic Data): 노출될 경우 개인식별 가능성이 있는 민감정보만 재현된 부분 재현 데이터
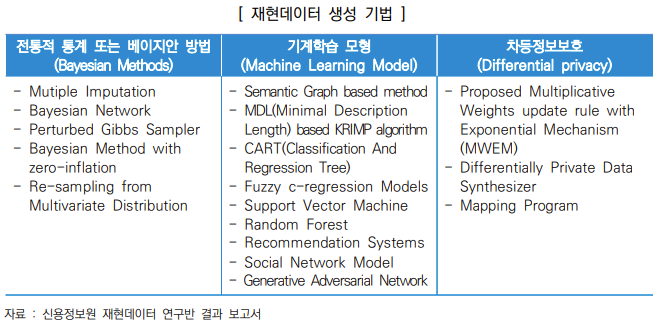
재현 데이터 생성 기법
생성 기법으로는 1. 전통적 통계 또는 베이지안 방법, 2. 기계학습 모형, 3. 차등정보보호가 있다.
생성 기법에 관해서는 활용도가 높은 CART와 GAN을 중심으로 다음 포스팅에서 작성하고자 한다.
*CART(Classification and regression trees)이란?
: 의사결정나무 알고리즘 중 하나로 분류와 회귀 모두 적용할 수 있어 지니불순도나 엔트로피 기준에 따라 데이터를 분기하여 트리를 생성하는 학습 방식
*GAN(Generative Adversarial Networks)이란?
: 적대적 생성 신경망으로 생성자(Generator)는 실제 데이터의 분포를 학습해 가짜 데이터를 생성하고, 판별자(Discriminator) 생성자가 만든 가짜 데이터를 구별하며 학습하는 경쟁적 학습 방식
재현 데이터 생성 라이브러리
재현 데이터를 생성하기 위한 도구로 Python 기반 라이브러리는 아래와 같으며, 다음 포스팅에서 SDV라이브러리와 R기반의 Synthpop 패키지를 소개하려 한다.
| 목적 | 라이브러리 | ||||
| 데이터 포인트 증가 | DataSynthesizer, SymPy | ||||
| 가짜 이름, 주소, 연락처, 날짜 정보 만들기 | Fakeer, Pydbgen, Minesis | ||||
| 관계형 데이터 생성 | Synthetic Data Vault (SDV) | ||||
| 완전 새로운 샘플 데이터 생성 | Platipy | ||||
| 시계열 데이터 | TimeSeriesGenerator, Synthetic Data Vault (SDV) | ||||
| 자동 생성 데이터 | Gretel Synthetics, Scikit-learn | ||||
| 복잡한 시나리오 | Mesa | ||||
| 이미지 데이터 | Zpy, Blender | ||||
| 비디오 데이터 | Blender | ||||
재현 데이터 성능 평가
재현 데이터를 검증 방식은 확정적으로 정립되지 않았으며, 연구에 따라 다양한 방식으로 검증하고 있다.
크게는 1. 유용성 지표, 2. 노출위험도 지표로 재현 데이터를 평가하고 있다.
1. 유용성 지표: 재현자료가 원본자료의 특성을 얼마나 유사하게 재현했는지 평가하는 지표
2. 노출위험도 지표: 재현자료의 프라이버시 보호 수준을 측정하는 지표. 원본자료의 값이 재현자료를 통해 노출될 가능성을 측정
일반적으로 유용성이 높을수록 노출 위험도가 증가한다.
여러 문헌과 사례를 보면 공공에서는 2. 노출위험도 지표에 대한 방법론을 연구하면서 신경을 쓰고 있지만, 대중은 1. 유용성 지표에 많이 치중하고 있어, 어느 정도 방법론이 제시되고 있다.
하지만, 생성 목적이 교육 및 사전테스트일 경우 재현 데이터가 얼마나 유사한지에 대해 깊은 검증을 요구하지 않는다.
➕ 유용성 지표
1. 실제 데이터와 재현 데이터의 EDA 및 시각화 비교
- 단변량, 이변량 분포 시각화로 두 데이터를 비교
- 평균, 표준편차, 중앙값, 사분범위(IQR) 등 통계량 비교
2. 재현 데이터를 이용한 모델 학습 및 검증
- 재현데이터를 Train set으로 학습하고, 실제데이터를 Test set으로 검증
- 실제데이터와 재현데이터 각각 모델 학습 및 검증을 통해 비교
3. 실제데이터와 재현데이터의 통계적 검정
- 숫자 데이터의 경우 콜모고르프-스미르노프(Kolmogorov-Smirnov) 검정
- 범주 데이터의 경우 총변동거리(TVD, Total Variation Distance) 계산
재현 데이터 사례
이해를 돕기 위해 간단하게 사례를 소개한다.
통계청
SDC통계데이서센터에서 통계기업등록부와 종사자-기업체 연계DB를 이용하여 재현 데이터를 생성하고 사전분석용으로 데이터를 제공하고 있다.
한국신용정보원
금융빅데이터개방시스템(CreDB)를 구축하여 개인신용정보, 기업신용정보, 보험신용정보를 모의DB로 생성하여 금융분야의 양질의 데이터를 개방하고 있다.
신용평가사(KCB)
성별, 직업, 신용등급, 나이, 연소득 등 민감함 마이크로 데이터를 재현 데이터로 만들어 데이터 스토어를 운영하고 있으며, 프로젝트로는 재현데이터를 이용하여 제주도 전입인구 특성 분석을 진행했다.

Reference
저널
유성준,박나리(2020), "CART 기법을 이용한 개인신용정보 재현자료 생성 기법", 통계청 통계개발원
이재근(2019), "진짜 같은 가짜! 재현데이터의 개념 및 활용 사례", 한국신용정보원
웹사이트
Turing(2022), "Synthetic Data Generation: Definition, Types, Techniques, and Tools", 접근일:2023-12-09,
https://www.turing.com/kb/synthetic-data-generation-techniques#why-is-synthetic-data-required?
IT위키(2021), "재현 데이터", 접근일:2023-12-09,
https://itwiki.kr/w/%EC%9E%AC%ED%98%84_%EB%8D%B0%EC%9D%B4%ED%84%B0#cite_note-1
KCB(2019), "제주도 전입인구 특성 분석", 접근일:2023-12-09,
https://datastore.koreacb.com/support/applicationCaseList.do
발표자료/매뉴얼
안정연(2023), "국가산업통계자료의 재현기법과 평가지표", 13회 국가통계방법론 심포지엄
박나리(2021), "CART 기법을 이용한 재현자료 작성: 기업통계등록부 및 종사자-기업체 연계DB", 11회 국가통계방법론 심포지엄
한국신용정보원빅데이터센터(2021), "기업신용정보 표본DB 이용자 매뉴얼(v1.1.1)", 금융빅데이터개방시스템 매뉴얼